 Sage . Mar 28th 2025 . 7 Min read
Sage . Mar 28th 2025 . 7 Min readHow to install the Sage 50 Accounting 2020 application
Here are some simple instructions for installing and configuring the Sage 50 Desktop on any device. These steps must be carried out in the proper sequence.
Step 1: Double-click on the Sage50_2020.exe file.

Figure 1.1
Step 2: After clicking on the Install tab, you will get an Install Shield Wizard prompt which displays the Requirements for the Sage 50 installation.
Click Install after reading the requirements.

Figure 1.2
Step 3: Before proceeding with the Sage 50 installation, you have to turn off the anti-virus software.

Figure 1.3
Step 4: Read the License Agreement carefully and agree on the terms of the license agreement by clicking the checkbox, and then click on Next.

Figure 1.4
Step 5: Tick on Auto Configure the Windows Firewall to allow installation and run Sage 50 (Recommended) and then click on Next.

Figure 1.5
Step 6: Enter the Serial Number.

Figure 1.6
The serial number can be found in your initial order email or in the download notification email for Sage 50.
If your serial number is not recognized, you can get assistance from the support team as shown in the link chat with support online.
After entering the serial number click on Next.
Step 7: Select the radio button Yes and click on Next.

Figure 1.7
Step 8: You can select the location to save the Sage 50 program files and Sage 50 company data files separately in your system.

Figure 1.8
Step 9: After selecting the locations, click on Install, now the installation will start.
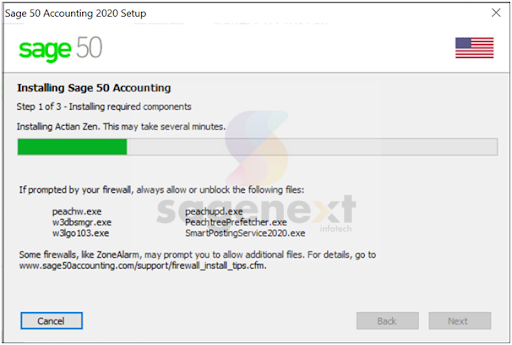
Figure 1.9
Step 10: To finish the installation, uncheck the Start Sage 50 Accounting checkbox and click on Finish, as shown in figure 1.10.

Figure 1.1
Step 11: Now you can open Sage 50 from the desktop.
Step 12: From the top bar menu, click on the Help tab. You will get a dropdown menu. From that, select Sage 50 Activation, Licensing, and Subscription Options.
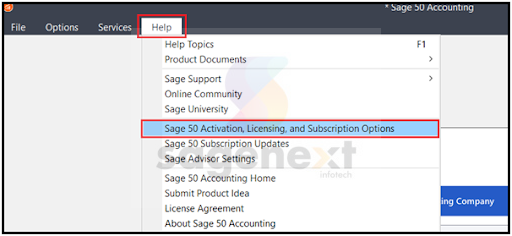
Figure 1.11
Step 13: Click on Activate Online Now

Figure 1.12
Step 14: Once the activation is done click OK

Figure 1.13
Step 15: Sage 50 is activated on your system now. You can restart your system and start using Sage 50.
Conclusion
By following these 15 steps, including accepting the license agreement, configuring firewall settings, entering the serial number, and activating the software, you can successfully install and configure Sage 50 Desktop on your device.
 written by
written by
